
What is a Relational Database?
It's a decade of databases, as they go mainstream. Learn what is a relational database and why are they important for your business?

When a collection of information is organized so that each data point has a defined relationship with other data points, a relational database is formed. Proposed by E. F. Codd in 1970, a relational database provides easy access to each data point.
In the case of this type of database, the data structures are kept separate from the physical storage. This feature proves to be of immense use to the data administrators who can now edit the physical data storage without altering or affecting the data's primary logical structure. The data structure mentioned here includes the data tables, indexes, and different views available.
In a relational database, the data is logically arranged in a structured and simplified manner. This will allow users to edit, alter, delete the data as and when required. The data is stored in structured tables and has a pre-defined logical construct. Relational databases are one of the most widely used forms of databases across the globe.
In addition to being popular, relational databases are highly reliable and serve as a better alternative to the traditional spreadsheet.
Definition of a Relational Database
Put in simple words; a relational database can be defined as a type of database that stores mutually related data points. It is a straightforward and direct way of representing data in related tables based on the relational model.
This relational model was designed to solve the problems that arose due to multiple and arbitrary data structures. It created a standard structure that was easy to understand and universal. This model could be used by any type or form of application, simplifying the work of developers and administrators.
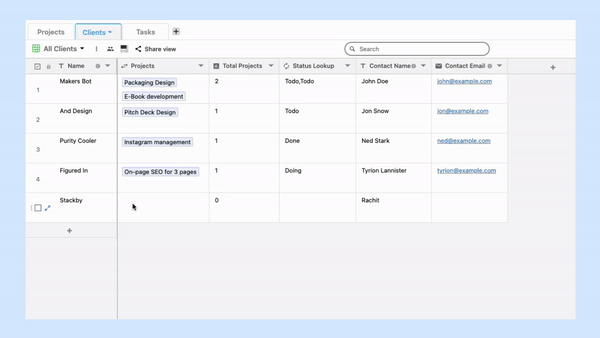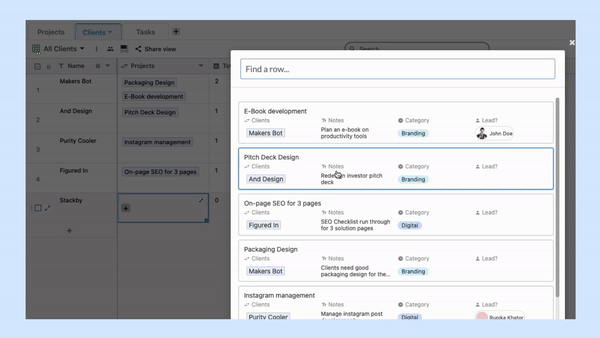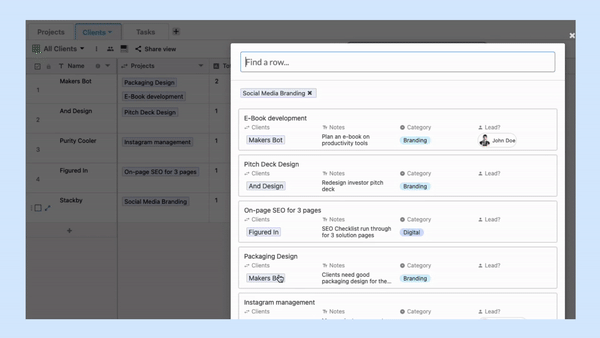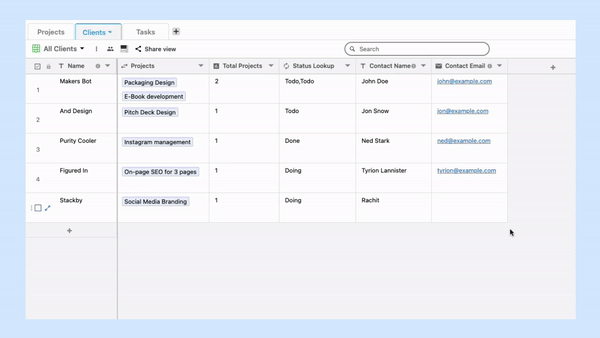
The tables, in the case of a relational database model, are known as relations.
Each table consists of one or more columns containing different data categories. The rows are also known as table records. They store data sets defined by the particular category. Users can access specific data sets by entering the required queries.
A relational database is essentially made up of rows (records) and columns (fields) if you’re new to this, this guide simplifies the concept clearly.
There was a time when the use of a database was the sole prerogative of professional developers. They were out of the reach of a common person in terms of both knowledge and scope. However, times have changed. With the right tools and a basic understanding, anyone can master the techniques used in a relational database or use tools like Stackby to build one in minutes.
All you have to do is get an idea about the overall structure and different components of a relational database, and you are all set to go! With a general idea, you will design and create your very own relational database that will meet all your data requirements and features.
Example of a Relational Databases
MySQL
MySQL is an open-source relational database management system that is widely used across the globe. It has the capability of supporting all the basic SQL commands. It is also integrated into WordPress sites. If you are working with MySQL and need to perform data extraction, transformation, and loading (ETL), you can explore MySQL ETL tools to streamline the process.
Oracle Database
Oracle Database is a high-performing multi-level relational database system created and operated by the Oracle Corporation. It offers scalability, reliability and security to the maximum extent.
Microsoft SQL Server
Developed by Microsoft, this is a relational database primarily used for storing and retrieving information when requested by other software applications.
How does a Relational Database work?
Accessing data from a complex and vast database can be quite a hassle. There are times when you might need to re-organize your data structure to extract the required data set.
A relational database eliminates the need to do just that! With the help of the relational model, you can access, alter, edit, and reassemble your data in several different formats without re-organizing your database tables.
A key feature of a relational database is its ability to separate the physical data structure from the logical backbone of the data. This allows administrators to manage the database without affecting or altering the logical structure. To understand the working of a relational database in depth, we need to understand the key terms used in its functioning.
A primary key is a unique identifier that is present in each table.
This primary key is used to identify the data or information in a particular table. Each row of the given table contains a unique instance of the primary key data for the categories that have been defined. This allows the application to identify and access a particular data set.
Consider the example where the primary key has been defined as the employee code. Each row of the table will contain a unique employee code such as ‘A123’, ‘B231’, ‘H918’, and so on. This will help identify that dataset.
In addition to this, the concept of a foreign key is also present. The function of the foreign key is to establish a logical connection between different tables. It can be described as a field in one table that connects to the primary key data present in another table.
The primary and foreign keys create relationships that help structure the relational database.
Related tables can share information easily without any form of data loss. A change in any one record is automatically recorded in the corresponding record of a different table. Before we go any further, it is important to understand the various kinds of relationships that can be defined.
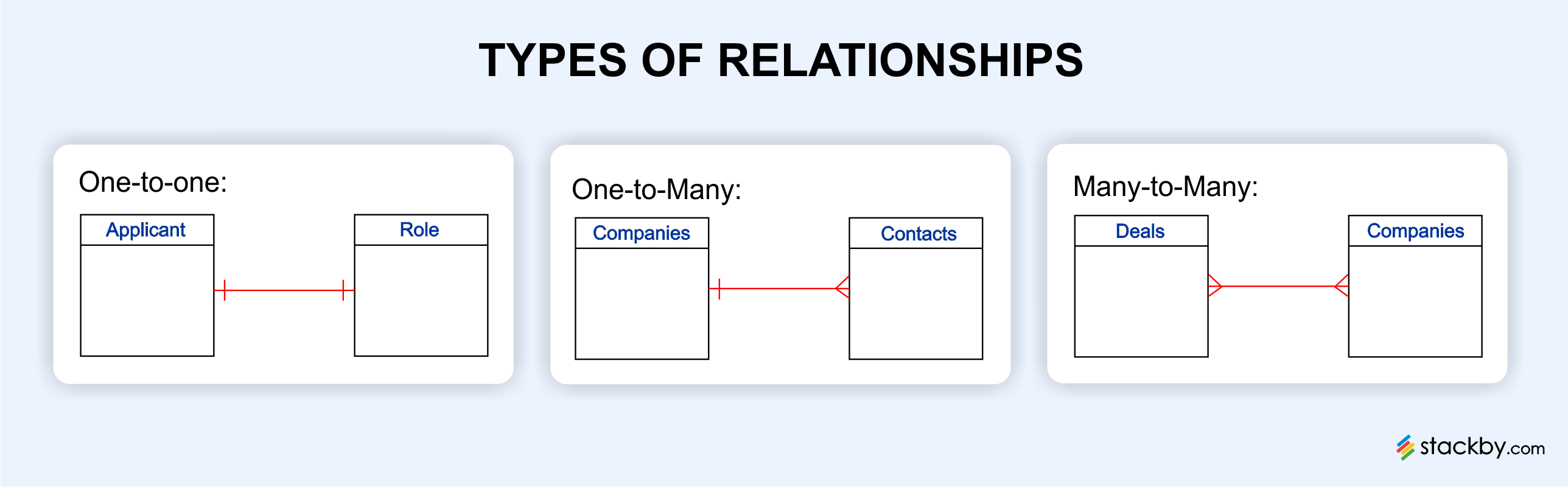
One-to-one relationship
This is the simplest form of relationship that can exist in a relational database. Here, one record in a table is associated with one record of another table. The relationship between an employee and their corresponding employee ID can be described as a one-to-one relationship.
One-to-many relationship
A one-to-many relationship is a relationship where a record of a particular table can be linked to multiple records of another table.
Many-to-many relationship
Here, multiple records of a table are linked to multiple records of another table.
Elements of a Relational Database
A relational database is composed of several different components that have each been described here in detail.
Table
The table forms the foundational elements of any relational database. It is the building block around which everything is structured. Put in simple words; it can be defined as collections of multiple intersecting rows and columns. The information in each table is logically organized and arranged.
Each table in a relational database represents data in a particular subject.
Consider an example where you are managing employee details for your company. There can be one table that stores all the personal details of the employees. You can have one table that stores their compensation details, their assigned roles and responsibilities, their contact details, and so forth. Each table provides a piece of the puzzle. The data present in the table is present in different records and fields.
Under the terms used in a relational database, a table is referred to as a relation. This concept is derived from set theory.
Record
The second element in this list is a record. A row in the table described above is referred to as a record.
While the table stores information on a particular subject, a row in the table refers to a record or an instance of the given subject.
Consider the same example as given above. Each record in your database of employee information will contain the details of one particular employee. The records present in a relational database are also referred to as tuples by many developers.
Get your free Excel spreadsheet for business expenses [2023]
At first glance, you might relate the term record to the simple rows present in any database or spreadsheet. However, the records of a relational database and the rows of a spreadsheet differ in some important aspects.
Firstly, the extent of flexibility present in a relational database is substantially high.
You don’t have to worry about the order of the records present in the database. You can alter and reorder the records according to your requirements. There are a number of options of databases available today that allow you to view the same data in the form of calendars, cards, grids, etc. The view or order of the data will not alter the underlying structure of the same.
A relational database, unlike a spreadsheet, helps you avoid duplicate data. This is because every record in a database is identified using a unique value. You cannot use the same value for multiple records. As a result, it becomes easy to find and identify a particular record.
You can alter or update any record as and when required. The added feature of a database is that a change made in a record in one part of the database will be reflected in the entire database. It becomes extremely easy to update the company’s data and eliminate any redundant information.
Field
Another name for this element of the relational database is a column. While the database represents an entire subject, a field or column represents a specific characteristic of the subject.
Let us take the same example forward. In a relational database storing employee information, the various fields can be employee ID, employee name, employee address, employee contact number, educational qualifications, etc. It is safe to say any relational database is a combination of records and fields.
The element field is also referred to as an attribute. In order to create a structured database, users are allowed to define the type of data that can be entered in the case of each field or attribute. If you’ve defined the data type that can be entered in a field, any user will not be allowed to enter any alternative data type.
In the given example, consider a field titled employee date of birth. If you set the data type to date, a user will not enter any other form of data. A similar situation arises if a user tries to enter a contact number in a field dedicated to an employee's email address. This is also referred to as a domain.
A domain is a set of permitted values for a particular relational database field. As already described above in detail, you cannot enter a value outside the scope of the domain.
Keys
For any user, keys are the most important part of the relational database. Several different keys are essential to the functioning of the database. Each key has a role to play that has been described here.
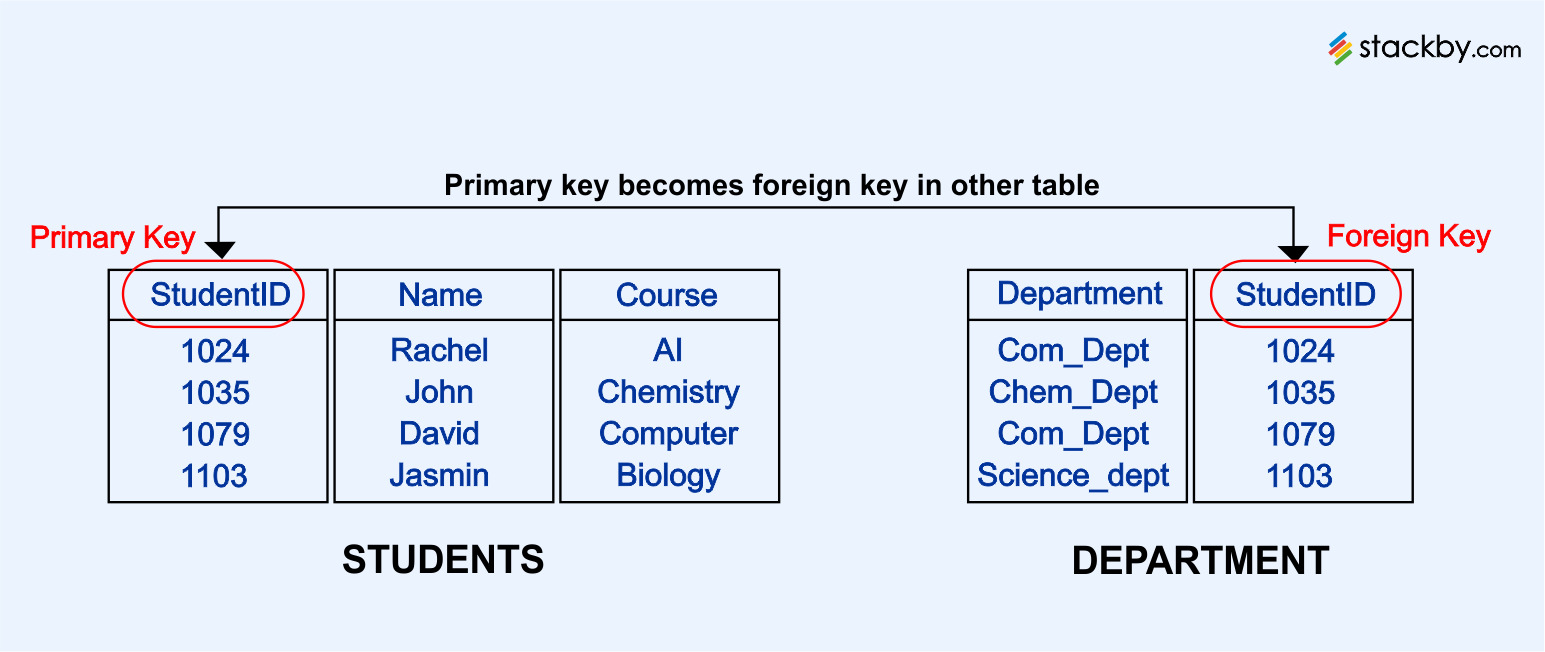
Primary Key – Remember the unique identifier we were talking about earlier? Well, the primary key holds the unique identifier for each record. It is used to identify the record and cannot be deleted from the database to ensure data integrity. As the name already suggests, the same key cannot be used for multiple records. It is unique to the record.
A primary key can take any format, that is, numbers, alphabet, alphanumeric, etc.
Foreign Key – Looking for a way to link two tables? Well, your solution is a foreign key. With the help of a foreign key, you can link a field in one table to the primary key present in another table. These keys function as a cross-referencing tool between different tables.
Besides a foreign key and a primary key, you also have several keys, such as a super key, a composite key, a candidate key, and an alternate key. They are not used as frequently as a primary key and a foreign key.
Instance and Schema
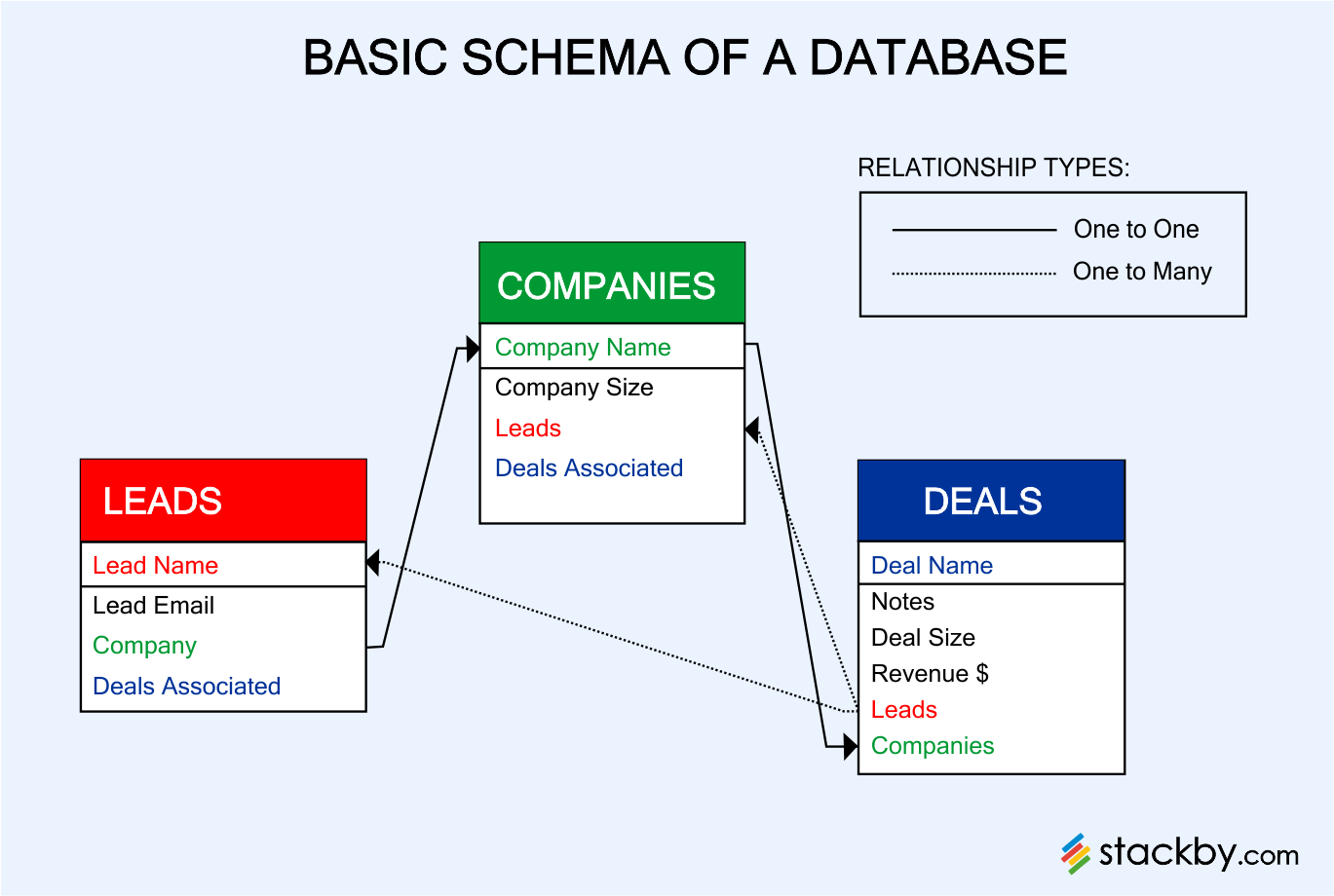
The design of the database is referred to as its schema. Schema can be defined at multiple levels: the physical schema, the logical schema, and the view schema.
The schema defines the outline of the organization of data - it is the visual representation of the database.
It gives the user an idea about the relationships that exist in the data and its corresponding structure. Besides, a schema also allows you to enforce data rules to maintain data integrity. In short, it can be described as a blueprint of the database structure.
On the other hand, a database instance is the data stored in a database at a particular moment. While the schema defines variables in the table, the corresponding value of the variable is stated by the instance of the database.
Advantages of a Relational Database
There is a reason why users worldwide prefer to turn to relational databases for their organizational data needs. The structure and design of such databases are highly flexible, efficient, effective, easy-to-use, and intuitive.
Relational databases offer several advantages over traditional spreadsheets and build forms of databases.
Accuracy
Data accuracy is extremely high in a relational database. Here, you can create multiple tables and link each other using primary and foreign keys. Since the structure. my relational database is more than any other kind of database.
Simplicity
The relational database allows users to store meaningful information in a structured manner. Besides, it is also extremely easy to handle. You do not require any form of coding experience to function with a database. It does not involve any complex structuring or difficult querying statements and processes. You can use simple and easy-to-understand queries to extract and alter data according to your requirements.
Accessibility
In addition to accuracy, another key feature or advantage of a relational database is its easy accessibility. Under normal circumstances, in most databases, you can only access the data stored by following a series of commands and making your way through the hierarchical structure.
However, in a relational database, a query can be entered and used by anyone who can access the data. Users can join multiple queries and use conditional statements to combine tables related to one another and extract the required data units. You can easily alter the data according to the set rules.
Data Integrity
One of the major concerns of any user is the assurance of data integrity. Companies tend to look for tools that will maintain the integrity of the entered data, even if multiple users are working on it. A relational database ensures that the entered data is in the right format, and all the relevant data required to establish relationships between tables is already present beforehand.
Using data queries and efficient data legitimacy validations, a relational database ensures data integrity. While data integrity is an important property in itself, it also promotes other advantages of the database, such as precision and stability of data.
Flexibility
The structure of a relational database is very accommodative and flexible. You can add, alter, modify, and delete the data according to your requirements at any point in time. There is no limit to the total number of rows, columns, and tables you can add and use. Any restriction that arises may be due to server limitations.
Normalization
The process of normalization provides a set of regulations, procedures, purposes, and characteristics to the structure of the database. It breaks down the data into multiple levels. Put in simple words; normalization makes the relational database more structured, stable, and reliable.
Data Security
The sudden loss of data due to unforeseen reasons is extremely problematic. Also, you might not want to give complete access to your database to everyone. Relational databases have even solved this problem. Since the data in this database is divided into multiple tables, the user can tag or mark specific tables as confidential, limiting the user access to such tables.
The process of setting up this restricted access system is also extremely simple. You can also set access levels for your team members and provide them with only the data they are required to work on.
Reduced Redundancy
Due to the normalization process, the data is separated for increased efficiency. This process also eliminates any possibility of data redundancy.
Backup and Recovery
Relational databases offer easy to export and import options. This ensures easy backup. You can even export the data while you are working to prevent any form of data loss. Currently, cloud-based relational databases have developed that facilitate continuous mirroring of data. You can recover all your data in a matter of mere seconds.
The advantages and varied features offered by relational databases are never-ending and constantly evolving for the better.
Migrating from Spreadsheet to Relational Database
While spreadsheets help in organizing data, they also suffer from several drawbacks. Unlike a relational database, they are not scalable. Besides, they are also prone to several errors. They require high manual maintenance and, in most cases, don’t integrate or connect to third party applications. A relational database, on the other hand, fills all the gaps in a spreadsheet.
What distinguishes a spreadsheet from a database? A schema. As already defined earlier, a schema represents the logical view of the entire database. It is absent in the case of a spreadsheet. There are hardly a few rules that govern the way a user can enter data in a spreadsheet. Lesser rules reduce the number of available programming capabilities.
Suppose you have to handle complex data and ensure the highest data integrity and security level. In that case, it is advisable to switch from a spreadsheet to a relational database. The question arises, how?
You can follow a few simple steps to migrate to a relational database.
Step 1 – Reviewing the existing database & exporting the database in CSV or Excel
You have to start with the most basic task of reviewing your present structure. Find out which workbooks you will migrate and how many worksheets are present in each of those workbooks. Export the data in the spreadsheet to CSV format or Excel format for simplified transfer.
Each worksheet that you will attempt to migrate will be organized in a combination of rows and columns. To simplify your work, you can also remove any columns designated for totals and subtotals. You can recreate them in the database using simple queries.
Step 2 – Defining the schema you want to add
The next step of the process is describing the relational database management system's schema. The function of a schema is the define the relationship between the entities of the database. Entities are just another term for tables in a database.
A schema will help you establish and maintain a relationship between the records of the table. It will establish and describe the structure in a formal and logical manner. You can consider the example of a librarian. The librarian wants to find out which book from the library was borrowed by which member and for what duration. Here, X denotes the user or member, Y denotes the books, and Z denotes the books on loan. A schema will draw a relation between the variables.
Step 3 – Use Importers in your database
Migrating to a relational database requires a proper mapping of the columns to ensure correct data transfer. You can use importers in your database to map and import columns in the database like Stackby.
Step 4 - Convert the columns into different data types
Each column has a specific data type according to the format of the data entered. You can assign and convert columns into different data types in Stackby to ensure that data is entered only in that particular format.
Step 5 – Normalize, Clean Up & Set your Workflow
This is the final step in the process. After you are done with the data migration, you can go through the data and remove any inconsistencies that might be present.
Continue building the database, like with any workflow - it'll grow and become better over time.

![A Simple Guide on Workflow Management Software [Updated 2026]](/blog/content/images/size/w960/2021/12/work-management-blog.png)
![Step by Step Guide on How to Build Forms in a Database [2026]](/blog/content/images/2022/03/form-database-blog.png)

